关于字符集和Unicode的相关知识
src url:http://www.blueidea.com/tech/program/2010/7432.asp
原文地址:http://www.joelonsoftware.com/articles/Unicode.html
作者:Joel Spolsky
译文:http://local.joelonsoftware.com/wiki/Talk:Chinese_(Simplified)
每个程序员都绝对必须知道的关于字符集和Unicode的那点儿事(别找借口!)
Unicode与字符集
你曾经是否觉得HTML中的"Content-Type"标签充满神秘?虽然你知道这个东西必须出现在HTML中,但对于它到底干吗你可能一无所知。
你是否曾经收到过来自你保加利亚朋友的邮件,到处都是"?????????????????"?
我很失望,因为我发现许多软件开发人员到现在为止都还没有对字符集、编码、Unicode有一个清晰的认识,这是个事实。几年前,在测试FogBUGZ项目时,忽然想看看它能不能接收用日文写的电子邮件。这个世界上会有人用日文写电子邮件?我不知道。测试结果很糟糕。我仔细看了用来解析MIME (Multipurpose Internet Mail Extenisons)格式的邮件所用的ActiveX控件,发现了它在字符集上面做的蠢事。于是我们不得不重新写一段代码,先消除Active控件的错误,然后再完成正确的转换。类似的事情在我研究另一个商业库的时候同样发生了,这个库关于字符编码这部分的实现简直糟透了。我找到它的开发者,把存在问题的包指给他,他却表示对于此无能为力。像很多程序员一样,他只希望这个缺陷会被人们遗忘。
事实并非如他所愿。因为我发现,像PHP这么流行的网页开发工具,竟然在实现上也完全忽略了多种字符编码的存在(译者注:这篇文章写于2003年,现在的 PHP可能已经纠正了这个问题吧),盲目地只使用8个比特来表示字符,于是开发优秀的国际化的Web应用程序变成了一场梦。我想说,受够了。
我申明:在2003年,如果你是一个程序员,但你却对字符、字符集、编码和Unicode一无所知,那么你别让我抓到你。如果落在我手里,我会让你待在潜水艇里剥六个月的洋葱,我发誓。
另外,还有一件事:
这个一点都不难。
在这篇文章里,我所讲的是每一个工作中的程序员都应该知道的知识。所有以为"纯文本 = ASCII码 = 一个字符就是8比特"的人不单单错了,而且错得离谱。如果你仍然坚持使用这种方式编写程序,那么你比一个不相信细菌的存在医生好不到哪里去。所以在你读完这篇文章以前,不要再写半行代码。
在我开始之前,必须说明白,如果你已经了解了国际化,可能你会觉得这篇文章过于简单。没错,我的的确确是想架一座最短的桥,让任何人都可以理解发生了什么事,懂得如何写出可以在非英文语言环境是正常工作的代码。还得指出,字符处理仅仅是软件国际化中的一小部分,但一口吃不成个胖子,今天我们只看什么是字符集
历史回顾
可能你以为我要开始谈非常古老的字符集如EBCDIC之类的,实际上我不会。EBCDIC与你的生活无关,我们不需要回到那么远。

回到一般远就行了。当Unix刚出来的时候,K&R写了《The C Programming Language》一书,那时一切都很简单。EBCDIC已经惭惭不用,因为需要表示的字符只有那些不带重音的英文字母,ASCII完全可以胜任。ASCII使用数字32到 127来表示所有的英文字母,比如空格是32,字母"A"是65等等。使用7个比特就可以存储所有这样字符。那个时代的大多数计算机使用8个比特来,所以你不但可以存储全部的ASCII,而且还有一个比特可以多出来用作其他。如果你想,你可以把它用作你不可告人的目的。32以下的码字是不可打印的,它们属于控制字符,像7表示响铃,12表示打印机换纸。
所有的一切都看起来那么完美,当然前提你生在一个讲英文的国家。

因为一个字节有8个比特,而现在只用了7个,于是很多人就想到"对呀,我们可以使用128-255的码字来表示其他东西"。麻烦来了,这么多人同时出现了这样的想法,而且将之付诸实践。于是IBM-PC上多了一个叫OEM字符集的东西,它包括了一些在欧洲语言中用到的重音字符,还有一些画图的字符,比如水平线、垂直线等,水平线在右端会带一个小弯钩,垂直线会如何等等。使用这些画图字符你可以画出漂亮的框、画出光滑的线条,在老式的烘干机上的8088电脑上你依然可以看到这些字符。事实上,当PC在美国之外的地方开始销售的时候,OEM字符集就完全乱套了,所有的厂商都开始按照自己的方式使用高128个码字。比如在有些PC上,130表示é,而在另外一些在以色列出售的计算机上,它可能表示的是希伯来字母ג,所以当美国人把包含résumés这样字符的邮件发到以色列时,就为变为rגsumגs。在大多数情况下,比如俄语中,高128个码字可能用作其他更多的用途,那么你如何保证俄语文档的可靠性呢?
最终ANSI标准结束了这种混乱。在标准中,对于低128个码字大家都无异议,差不多就是ASCII了,但对于高128个码字,根据你所在地的不同,会有不同的处理方式。我们称这样相异的编码系统为码页(code pages)。举个例子,比如在以色列发布的DOS中使用的码页是862,而在希腊使用的是737。它们的低128个完全相同,但从128往上,就有了很大差别。MS-DOS的国际版有很多这样的码页,涵盖了从英语到冰岛语各种语言,甚至还有一些"多语言"码页。但是还得说,如果想让希伯来语和希腊语在同一台计算机上和平共处,基本上没有可能。除非你自己写程序,程序中的显示部分直接使用位图。因为希伯来语对高128个码字的解释与希腊语压根不同。
同时,在亚洲,更疯狂的事情正在上演。因为亚洲的字母系统中要上千个字母,8个比特无论如何也是满足不了的。一般的解决方案就是使用DBCS- "双字节字符集",即有的字母使用一个字节来表示,有的使用两个字节。所以处理字符串时,指针移动到下一个字符比较容易,但移动到上一个字符就变得非常危险了。于是s++或s--不再被鼓励使用,相应的比如Windows下的AnsiNext和AnsiPrev被用来处理这种情况。
可惜,不少人依然坚信一个字节就是一个字符,一个字符就是8个比特。当然,如果你从来都没有试着把一个字符串从一台计算机移到另一台计算机,或者你不用说除英文以外的另一种语言,那么你的坚信不会出问题。但是互联网出现让字符串在计算机间移动变得非常普遍,于是所有的混乱都爆发了。非常幸运,Unicode适时而生。
Unicode
Unicode 是一个勇敢的尝试,它试图用一个字符集涵盖这个星球上的所有书写系统。一些人误以为Unicode只是简单的使用16比特的码字,也就是说每一个字符对应 16比特,总共可以表示65536个字符。这是完全不正确的。不过这是关于Unicode的最普遍的误解,如果你也这样认为,不用感到不好意思。
事实上,Unicode使用一种与之前系统不同的思路来考虑字符,如果你不能理解这种思路,那其他的也就毫无意义了。
到现在为止,我们的做法是把一个字母映射到几个比特,这些比特可以存储在磁盘或者内存中。
A -> 0100 0001
在Unicode中,一个字母被映射到一个叫做码点(code point)的东西,这个码点可以看作一个纯粹的逻辑概念。至于码点(code point)如何在内存或磁盘中存储是另外的一个故事了。
在Unicode中,字母A可看做是一个柏拉图式的理想,仅存在于天堂之中:(我的理解是字母A就是一个抽象,世界上并不存在这样的东西,如果数学里面的0、1、2等一样)
A
这个柏拉图式的A与B不同,也与a不同,但与A和A相同。这个观点就是Times New Roman字体中的A与Helvetica字体中的A相同,与小写的"a"不同,这个应该不会引起太多的异议。但在一些语言中,如何辨别一个字母会有很大的争议。比如在德语中,字母 ß是看做一个完整的字母,还是看做ss的一种花式写法?如果在一个字母的形状因为它处在一个单词的末尾而略有改变,那还算是那个字母吗?阿拉人说当然算了,但希伯来人却不这么认为。但无论如何,这些问题已经被Unicode委员会的这帮聪明人给解决了,尽管这花了他们十多年的时间,尽管其中涉及多次政治味道很浓的辩论,但至少现在你不用再为这个操心了,因为它已经被解决。
每一个字母系统中的每一个柏拉图式的字母在Unicode中都被分配了一个神奇的数字,比如像U+0639。这个神奇数字就是前面提到过的码点(code point)。U+的意思就是"Unicode",后面跟的数字是十六进制的。U+0639表示的是阿拉伯字母Ain。英文字母A在Unicode中的表示是U+0041。你可以使用Windows 2000/XP自带的字符表功能或者Unicode的官方网站(www.unicode.org)来查找与字母的对应关系。
事实上Unicode可以定义的字符数并没有上限,而且现在已经超过65536了。显然,并不是任何Unicode字符都可以用2个字节来表示了。
举个例子,假设我们现在有一个字符串:
Hello
在Unicode中,对应的码点(code point)如下:
U+0048 U+0065 U+006C U+006C U+006F
瞧,仅仅是一堆码点而已,或者说数字。不过到现在为止,我们还没有说这些码点究竟是如何存储到内存或如何表示在email信息中的。
编码
要存储,编码的概念当然就被引入进来。
Unicode最早的编码想法,就是把每一个码点(code point)都存储在两个字节中,这也就导致了大多数人的误解。于是Hello就变成了:
00 48 00 65 00 6C 00 6C 00 6F
这样对吗?如下如何?
48 00 65 00 6C 00 6C 00 6F 00
技术上说,我相信这样是可以的。事实上,早期的实现者们的确想把Unicode的码点(code point)按照大端或小端两种方式存储,这样至少已经有两种存储Unicode的方法了。于是人们就必须使用FE FF作为每一个Unicode字符串的开头,我们称这个为Unicode Byte Order Mark。如果你互换了你的高位与低位,就变成了FF FE,这样读取这个字符串的程序就知道后面字节也需要互换了。可惜,不是每一个Unicode字符串都有字节序标记。
现在,看起来好像问题已经解决了,可是这帮程序员仍在抱怨。"看看这些零!"他们会这样说,因为他们是美国人,他们只看不会码点不会超过U+00FF的英文字母。同时他们也是California的嬉皮士,他们想节省一点。如果他们是得克萨斯人,可能他们就不会介意两倍的字节数。但是这样California节俭的人却无法忍受字符串所占空间翻倍。而且现在大堆的文档使用的是ANSI和DBCS字符集,谁去转换它们?于是这帮人选择忽略Unicode,继续自己的路,这显然让事情变得更糟。
于是非常聪明的UTF-8的概念被引入了。UTF-8是另一个系统,用来存储字符串所对应的Unicode的码点 (code points)-即那些神奇的U+数字组合,在内存中,而且存储的最小单元是8比特的字节。在UTF-8中,0-127之间的码字都使用一个字节来存储,超过128的码字使用2,3甚至6个字节来存储。
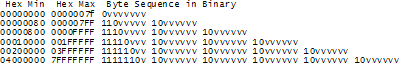
这显然有非常好的效果,因为英文的文本使用UTF-8存储的形式完全与ASCII一样了,所以美国人压根不会注意到发生了什么变化。举个例子,Hello -- U+0048 U+0065 U+006C U+006C U+006C U+006F,将会被存储为48 65 6C 6C 6F,这与ASCII、与ANSI标准、与所有这个星球上的OEM字符集显然都是一样的。现在,如果你需要使用希腊字母,你可以用几个字节来存储一个码字,美国人永远都不会注意到。(干吗得美国人注意,无语,美国人写的文章...)
到现在我已经告诉了你三种Unicode的编码方式,传统的使用两个字节存储的称之为UCS-2或者UTF-16,而且你必须判断空间是大端的UCS-2还是小端的UCS-2。新的UTF-8标准显然更流行,如果你恰巧有专门面向英文的程序,显然这些程序不需要知道UTF-8的存在依然可以工作地很好。
事实上,还有其它若干对Unicode编码的方法。比如有个叫UTF-7,和UTF-8差不多,但是保证字节的最高位总是0,这样如果你的字符不得不经过一些严格的邮件系统时(这些系统认为7个比特完全够用了),就不会有信息丢失。还有一个UCS-4,使用4个字节来存储每个码点(code point),好处是每个码点都使用相同的字节数来存储,可惜这次就算是得克萨斯人也不愿意了,因为这个方法实在太浪费了。
现在的情况变成了你思考事情时所使用的基本单元--柏拉图式的字母已经被Unicode的码点完全表示了。这些码点也可以完全使用其它旧的编码体系。比如,你可以把 Hello对应的Unicode码点串(U+0048 U+0065 U+006C U+006C U+006F)用ASCII、OEM Greek、Hebrew ANSI或其它上百个编码体系来编码,不过需要注意一点,有些字母会无法显示。如果你要表示的Unicode码点在你使用的编码体系中压根没有对应的字符,那么你可能会得到一个小问号"?",或者得到一个"�"。
许多传统的编码体系仅仅能编码Unicode码点中的一部分,其余全部会被显示为问号。比较流行的英文编码体系有Windows-1252(Windows 9x中的西欧语言标准)和ISO-8859-1,还有aka Latin-1。但是如果想用这些编码体系来编码俄语或者希伯来语就只能得到一串问号了。UTF 7,8,16,和32都可以完全正确编码Unicode中的所有码点。
关于编码的唯一事实
如果你完全忘掉了我刚刚解释过的内容,没有关系,请记住一点,如果你不知道一个字符串所使用的编码,这个字符串在你手中也就毫无意义。你不能再把脑袋埋进沙中以为"纯文本"就是ASCII。事实上,
根本就不存在所谓的"纯文本"。
那么我们如何得知一个字符串所使用的空间是何种编码呢?对于这个问题已经有了标准的作法。如果是一份电子邮件,你必须在格式的头部有如下语句:
Content-Type: text/plain; charset="UTF-8"
对于一个网页,传统的想法是Web服务器会返回一个类似于Content-Type的http头和Web网页,注意,这里的字符编码并不是在HTML中指出,而是在独立的响应headers中指出。
这带来了一些问题。假设你拥有一个大的Web服务器,拥有非常多的站点,每个站点都包括数以百计的Web页面,而写这些页面的人可能使用不同的语言,他们在他们自己计算机上的FrontPage等工具中看到页面正常显示就提交了上来,显然,服务器是没有办法知道这些文件究竟使用的是何种编码,当然 Content-Type头也没有办法发送了。
如果可以把Content-Type夹在HTML文件中,那不是会变得非常方便?这个想法会让纯粹论者发疯,你如何在不知道它的编码的情况下读一个HTML文件呢?答案很简单,因为几乎所有的编码在32-127的码字都做相同的事情,所以不需要使用特殊字符,你可以从HTML文件中获得你想要的Content-Type。
<html>
<head>
<meta http-equiv="Conent-Type" content="text/html" charset="utf-8">
注意,这里的meta标签必须在head部分第一个出现,一旦浏览器看到这个标签就会马上停止解析页面,然后使用这个标签中给出的编码从头开始重新解析整个页面。
如果浏览器在http头或者meta标签中都找不到相关的Content-Type信息,那应该怎么办?Internet Explorer做了一些事情:它试图猜测出正确的编码,基于不同语言编码中典型文本中出现的那些字节的颇率。因为古老的8比特的码页(code pages)倾向于把它们的国家编码放置在128-255码字的范围内,而不同的人类语言字母系统中的字母使用颇率对应的直方图会有不同,所以这个方法可以奏效。虽然很怪异,但对于那些老忘记写Content-Type的幼稚网页编写者而言,这个方法大多数情况下可以让他们的页面显然OK。直到有一天,他们写的页面不再满足"letter-frequency-distribution",Internet Explore觉得这应该是朝鲜语,于是就当朝鲜语来显示了,结果显然糟透了。这个页面的读者们立刻就遭殃了,一个保加利亚语写的页面却用朝鲜语来显示,效果会怎样?于是读者使用 查看-->编码 菜单来不停地试啊试,直到他终于试出了正确的编码,但前提是他知道可以这样做,事实上大多数人根本不会这样做。
在我的公司开发的一款Web页面管理软件CityDesk的最新版本中,我们决定像Visual Basic、COM和Windows NT/2000/XP所做的那样,整个过程中使用UCS-2(两个字节)Unicode。在我们写的C++代码中,我们把所有的char类型换成了wchar_t,所有使用str函数的地方,换成了相应的wcs函数(如使用wcscat和wcslen来替代strcat和strlen)。如果想在C中创建一个UCS-2的字符串,只需在字符串前面加L即可:L"Hello"。
当CityDesk发布页面的时候,它把所有的页面都转换成了UTF-8编码,而差不多所有的浏览器都对UTF-8有不错的支持。这就是"Joel On Software"(就是作者的首页)编码的方式,所以即使它拥有29个语言版本,至今也未听到有一个人抱怨页面无法浏览。
这篇文章已经有点长了,而且我也没有办法告诉你关于字符编码和Unicode的所有应该了解的知识,但读到现在我想你已经掌握到基本的概念,回去编程时可以使用抗生素而不是蚂蝗和咒语了,这就看做是留给你的作业吧。
本文链接:http://www.blueidea.com/tech/program/2010/7432.asp
分享到:




相关推荐
Java,每一个软件开发人员绝对必须掌握的关于 Unicode 和字符集的最基础的知识
Unicode 和字符集的最基础的知识
unicode和ansi字符集的区别差异
字符必须编码后才能被计算机处理。计算机使用的缺省编码方式就是计算机的内码。早期的计算机使用7位的ASCII编码,为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5....
字符集概述和C++应用 ANIS Unicode,UTF-8字符集知识介绍
早期的UNICODE 版本里,认为UNICODE 应该是一个固定长度的字符集,用一个16 位的整数来表示一个字符,也就是说一个UNICODE 字符占用2 个字节的存储空间。一个 16 位的整数的范围是0~65535,所以早期版本的UNICODE ...
详细描述了:字符编码ASCII、GB2312、Unicode、UTF-8区别。
这个PPT课件介绍了Unicode和字符编码相关的知识。丰富生动的图片和讲解使您能快速地掌握Unicode编码相关的知识,是不可多得的Unicode相关的PPT教程。 内容提要: ----------------- 1. 计算机编码 2. 内码、字形...
导读:本文来自『墨天轮』专栏“循序渐进Oralcle”(https://www.modb.pro/topic/6289,复制到浏览器中打开或者点击“阅读原文”)...这篇介绍第三章的3.1-3.4:字符集的基本知识、数据库的字符集、字符集文件及字符支
本文主要包括以下几个方面:编码基本知识,java,系统软件,url,工具软件等。在下面的描述中,将以"中文"两个字为例,经查表可以知道其GB2312编码是"d6d0 cec4",Unicode编码为"4e2d 6587",UTF编码就是"e4b8ad e...
关于I18N字符集 的问题。了解更多关于unicode的知识。
本文主要包括以下几个方面:编码基本知识,java,系统软件,url,工具软件等。 最早的编码是iso8859-1,和ascii编码相似。...sqlserver里面有char和nchar,那个n据说是指unicode的数据,这个是什么意思。
ISO/IEC 8859编码标准中的15种字符集 A.3. Code Page表格 A.3.1. 常见的ANSI和OEM的Code Page的表格 A.3.1.1. ANSI Code Page表 A.3.1.2. OEM Code Page表 A.3.1.3. ANSI和OEM共有的Code Page表 A.3.1.4. 其他一些...
微软的那个臭屁的JOEL(就是写《JOEL说软件》的那个牛人)曾说:“每一位软件开发人员必须、绝对要至少具备UNICODE与字符集知识(没有任何例外)”,我也常常困扰于字符集的转换等很多问题,所以这次下决心要把他搞...
字符内部Unicode字符编码,占2个字节,可表示0~216-1(65535)个字符,通常用一对单引号引用,如:‘a’,‘5’等。 字符数据类型(char) ASCII 码是 Unicode 码的一个子集,用 Unicode 表示 ASCII 码时,可表示其前...
6.3.2 消息排序 6.3.3 控制字符的处理 6.3.4 死字符消息 6.4 键盘消息和字符集 6.4.1 KEYVIEW1程序 6.4.2 非英语键盘问题 6.4.3 字符集和字体 6.4.4 Unicode解决方案 6.4.5 TrueType字体和大字体 6.5 插入符号(不是...
10.3.7. 字符串文字字符集和校对 10.3.8. 在SQL语句中使用COLLATE 10.3.9. COLLATE子句优先 10.3.10. BINARY操作符 10.3.11. 校对确定较为复杂的一些特殊情况 10.3.12. 校对必须适合字符集 10.3.13. 校对效果的示例 ...
10.3.7. 字符串文字字符集和校对 10.3.8. 在SQL语句中使用COLLATE 10.3.9. COLLATE子句优先 10.3.10. BINARY操作符 10.3.11. 校对确定较为复杂的一些特殊情况 10.3.12. 校对必须适合字符集 10.3.13. 校对效果的示例 ...
10.3.7. 字符串文字字符集和校对 10.3.8. 在SQL语句中使用COLLATE 10.3.9. COLLATE子句优先 10.3.10. BINARY操作符 10.3.11. 校对确定较为复杂的一些特殊情况 10.3.12. 校对必须适合字符集 10.3.13. 校对效果的示例 ...
10.10. MySQL支持的字符集和校对 10.10.1. Unicode字符集 10.10.2. 西欧字符集 10.10.3. 中欧字符集 10.10.4. 南欧与中东字符集 10.10.5. 波罗的海字符集 10.10.6. 西里尔字符集 10.10.7. 亚洲字符集 11. 列...